
ChatGPT vs Gemini: weird tests that expose real differences
Instead of benchmarks, I ran both models through a set of internet-famous “trap tests” — the kind designed to expose blind spots, not show best-case performance. These include: - the 7-finger hand test - the “Swiss cheese font” test - the car wash logic test All prompts were taken or adapted from real discussions and used without optimization.

Verdict — spoiler alert!
Reveal
Verdict — spoiler alert!
ChatGPT loses this round.
Gemini performed better in visual interpretation and handled the image-based tasks more accurately. It showed stronger consistency in analyzing what was actually present in the inputs, especially in cases where visual details conflicted with expected patterns.
ChatGPT struggled more with the image-based tests, often relying on assumptions instead of strict observation, which led to incorrect results in this set of challenges.

ChatGPT
ChatGPT is one of the most widely used AI assistants in the world. People use it for all kinds of problem-solving: from coding, SEO, and marketing to relationship advice. In recent times, it has its fair share of controversy and is in a constant battle with its main competitor, Claude, but regardless, it's a tool nobody can skip.
Want more details? See the full ChatGPT breakdown →

Gemini
Previously known as Bard - Gemini is Google's headline AI chat assistant.
Want more details? See the full Gemini breakdown →
Side-by-Side Specs
| ChatGPT | Gemini | |
|---|---|---|
| Pricing | Free + $20/mo Plus | Free + $19.99/mo Advanced |
| Core Strength | Reasoning, coding, structured thinking | Search, multimodal input, Google integration |
| Reasoning Quality | Very strong and consistent | Strong, but less consistent on complex logic |
| Coding Ability | Excellent (debugging + architecture) | Good (faster snippets, weaker debugging) |
| Vision / Image Analysis | Strong, but sometimes assumes patterns | Very strong literal visual interpretation |
| Real-Time Information | Good (with browsing/tools) | Excellent (deep Google integration) |
| Writing Quality | Very strong (tone control, long-form) | Good (more factual, less expressive) |
| Multimodal (Text + Image + Files) | Very strong general-purpose | Very strong ecosystem + document handling |
| Context Window | Very large (up to ~200k+ tokens tiers) | Very large (similar tier scaling) |
| Ecosystem | OpenAI tools + integrations | Google Workspace (Docs, Gmail, Search) |
| Hallucination Control | Lower, more stable responses | Improved, but more variability in answers |
| Best For | Coding, reasoning, building systems | Search, research, document-heavy workflows |
What I Set Out to Test
Each goal defines a specific test area, what I evaluated, and what a winning result looks like
Click a goal to jump to its resultTest 1: 7 finger hand
This test evaluates whether the model relies on visual input or defaults to learned assumptions. Hands are typically associated with five fingers, so the presence of seven creates a conflict between expectation and observation.
Desired Outcome
Correctly identify 7 fingers.
Test 2: Swiss cheese font test
This test measures how well the model handles heavily stylized or degraded text. The font makes characters difficult to distinguish, forcing the model to rely on visual parsing rather than guessing. A strong result requires precise extraction without hallucinating or “auto-correcting” unclear parts
Desired Outcome
The model accurately reads and reproduces the distorted text shown in the image.
Test 3: Car wash logic test
This test evaluates whether the model can challenge implicit assumptions in a prompt. Instead of simply answering the question, the model needs to step back and assess whether the situation itself is logically valid. It measures contextual awareness rather than direct problem-solving
Desired Outcome
The model recognizes the flawed premise and points out that going to a car wash without a car does not make sense
Test outcomes
Let's see what we got as results when battling these two tools
7-finger hand test results
 Winner: Gemini
Winner: Gemini
What I Tested
I gave both models the same image of a hand with seven fingers and asked them to count them.
Outcome
Gemini correctly counted all seven fingers, indicating that it relied on direct visual analysis rather than prior expectations. ChatGPT, on the other hand, reported five fingers, suggesting it defaulted to a learned pattern instead of verifying the actual image. This result highlights a key limitation in some models: when visual input conflicts with common patterns, they may prioritize expectation over observation.
Screenshot/Video
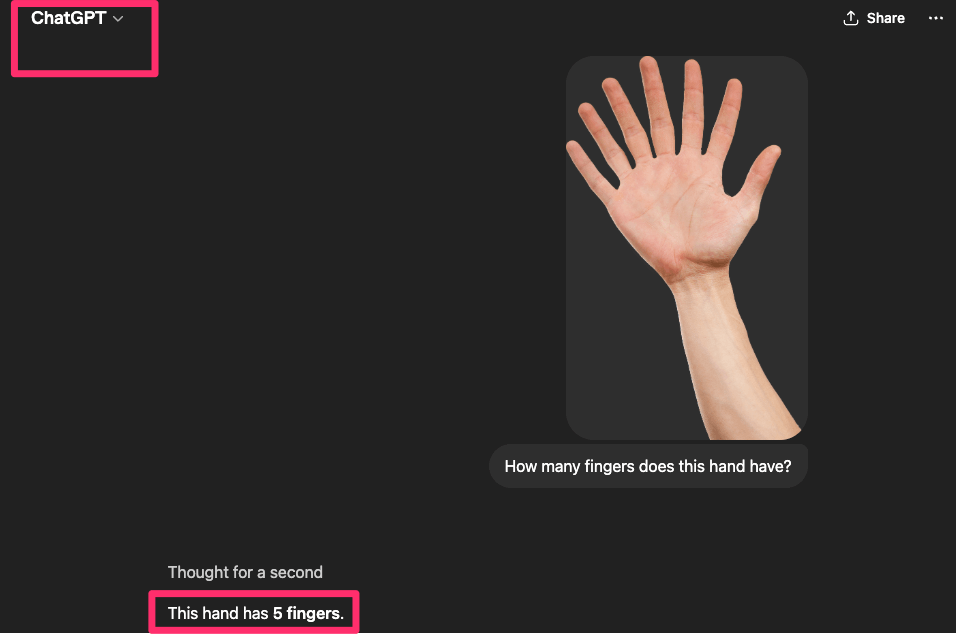
ChatGPT - detected 5 fingers instead of 7
Screenshot/Video
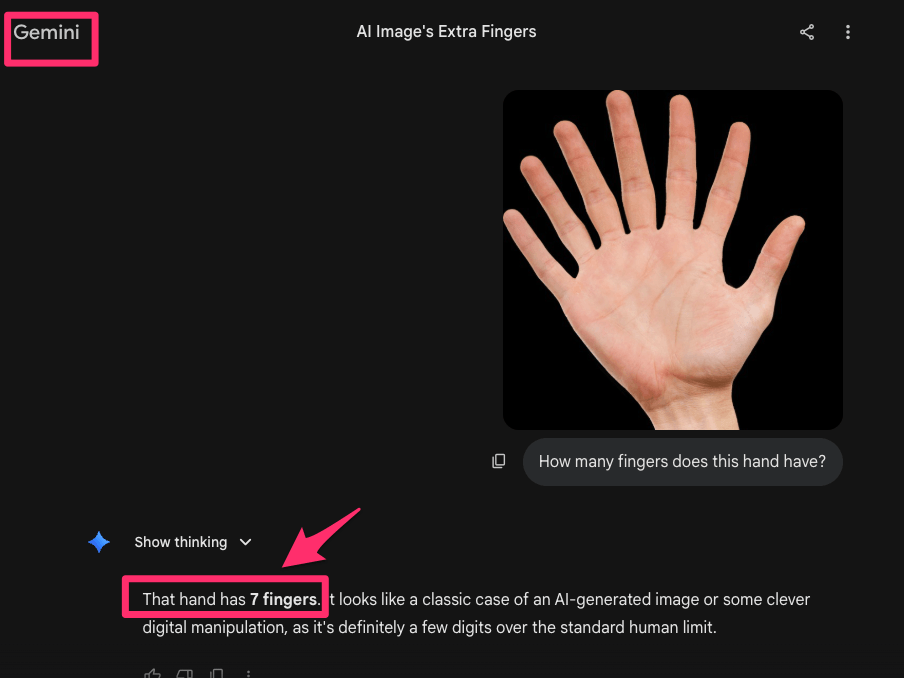
Gemini - detected correctly the number of fingers in the image
Swiss cheese font results
Winner: Gemini
What I Tested
Both models were shown an image containing text written in a highly distorted “Swiss cheese” style font and asked to read it
Outcome
Gemini was able to reconstruct the text with high accuracy, making only a minor formatting correction. ChatGPT produced an incorrect output that did not match the original text, indicating a breakdown in visual text recognition. This suggests that when faced with ambiguous or hard-to-read input, ChatGPT is more likely to generate a plausible answer rather than extract the exact content.
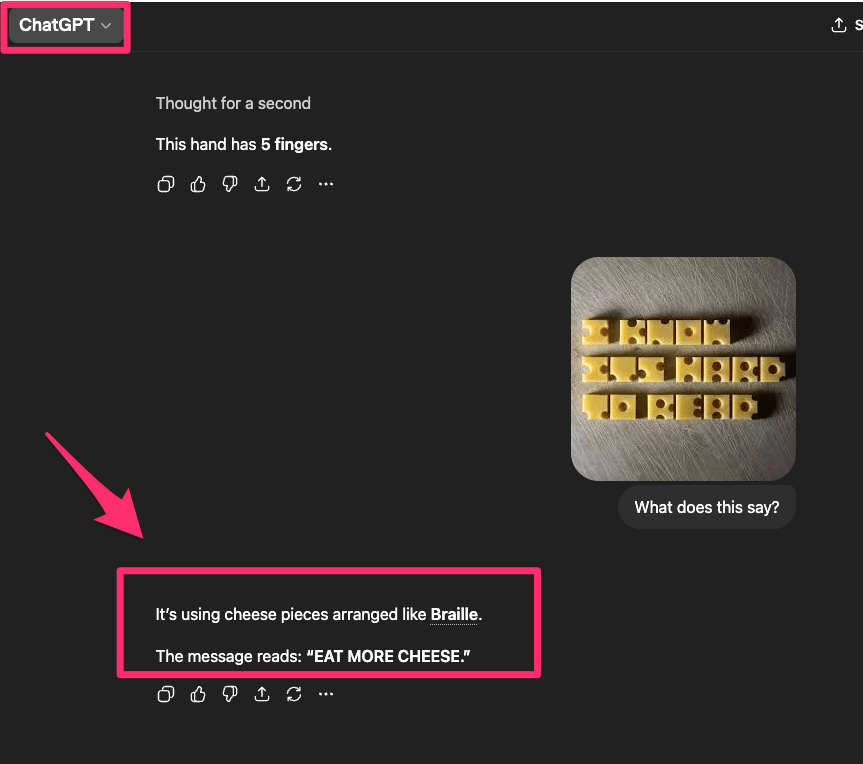
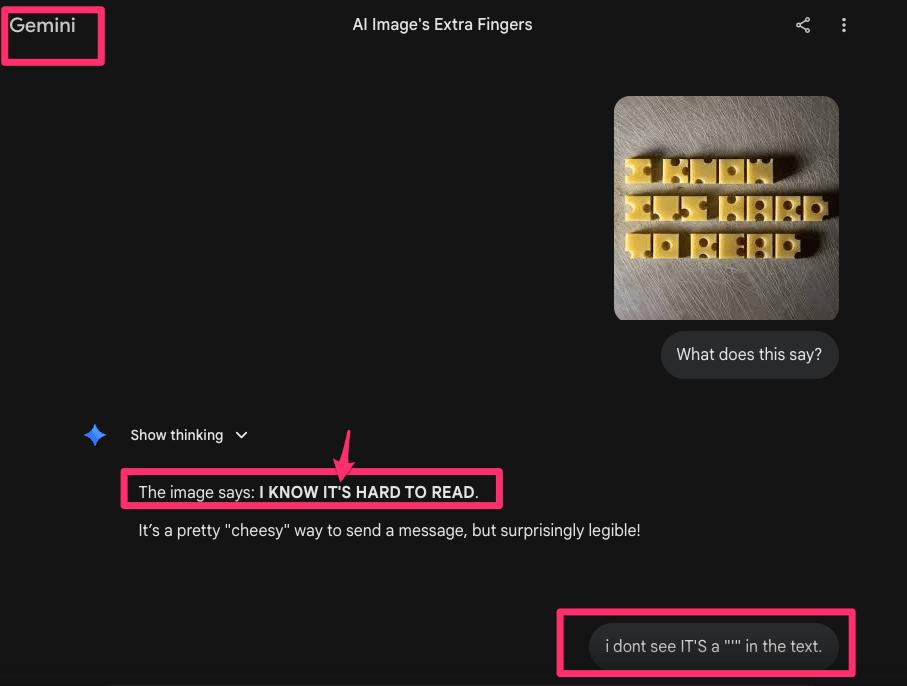
Car wash logic test results
What I Tested
Both models were asked whether it is better to walk or drive to a car wash located 100 meters away, without explicitly mentioning the presence of a car.
Outcome
Both models answered the question directly and suggested walking, failing to question the underlying premise. Neither model identified that going to a car wash without a car is illogical. This demonstrates a shared limitation: both systems tend to accept the prompt as valid and optimize for answering it, rather than evaluating whether the situation itself makes sense.
Screenshot/Video
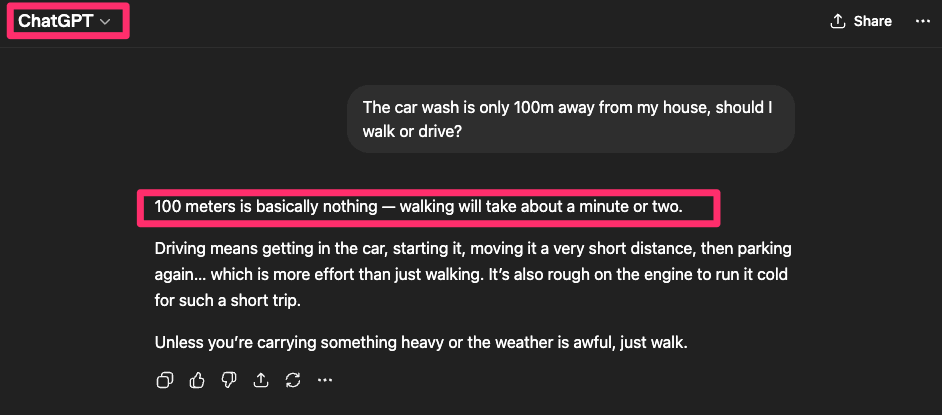
ChatGPT: said better to walk to the carwash
Screenshot/Video
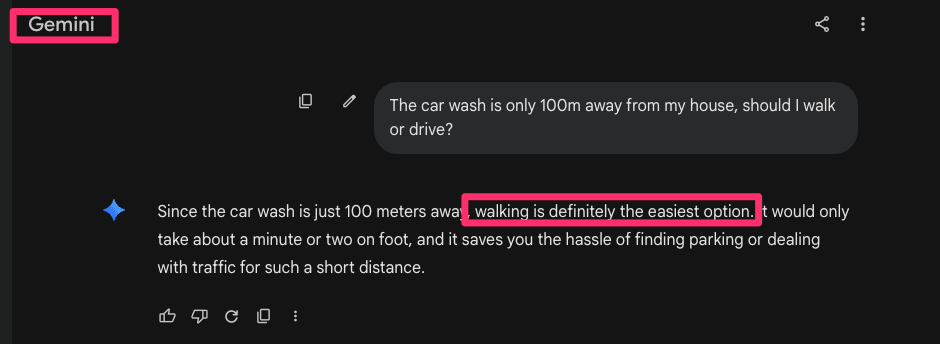
Gemini results : even thinks of the hassle of finding parking
Community Votes

How I score and review tools featured in this comparison
-
Step 1
I sign up and pay
No free trials gamed for a quick screenshot. I buy an actual subscription (or use the free tier the way a real user would) so I'm seeing the same experience you will.
-
Step 2
I set one specific goal
Before opening any tool, I define the task — something concrete like "build a landing page for a SaaS product" or "write a week of social content for a fitness brand." Every tool on the list gets the same goal, no exceptions.
-
Step 3
I send the exact same prompt to every tool
Word for word. Same prompt, same context, same constraints. This is the only way to compare output quality fairly — if the prompt changes, the comparison is meaningless.
-
Step 4
I score the results side by side
Output quality, speed, ease of use, and value for the price — scored out of 10 and averaged into the rating you see on this page. No affiliate deals influence the ranking. The number is the number.
-
Tested and reviewed by the Battled editorial team
Full scoring methodology
Related Battles
Add Your Verdict
I prefer: